
量化回测中的幸存者偏差现象
当使用在财经新闻中找到的当前指数成分进行回测时,数据通常仅包含“幸存者”,结果自然会被隐形的优化。但是回到过去,我们是无法判断哪些股票会出问题,从而提前避开的。


关于幸存者偏差
幸存者偏差或幸存者偏误(英语:survivorship bias),也称为生存者偏差,是一种逻辑谬误,属于选择偏差的一种。当过度关注“幸存”的人事物,从而造成忽略那些没有幸存的(也可能因为无法观察到),便会得出错误的结论。
第二次世界大战期间,美国哥伦比亚大学统计学亚伯拉罕·沃德教授在计算如何减少轰炸机因敌方炮火而遭受的损失时,将“幸存者偏差”纳入到计算中。其研究小组检查了执行任务返回的飞机所受到的损坏。与没有将本概念纳入计算不同的是,他建议在损坏最少的区域增加装甲,而并非在弹孔最多的地方增加装甲。因为返回飞机上的弹孔代表了轰炸机可能受到损伤但仍足够安全地返回基地的区域,而那些完全没有弹孔的地方,一旦中弹就完全没有返回的机会,而完全不会出现在研究的样本中。所以沃德教授建议美国海军在返航飞机上未受伤的区域增加防护,并推断这些地方被击中是会导致飞机最有可能损失。他的这项研究对当时仍在发展初期的运筹学领域具有深远的影响。
量化测试中的幸存者偏差
就像返回基地的飞机一样,在纳斯达克或纽约证券交易所上市的公司,特别是在一些大型的指数成分股中存在“幸存者偏差现象”。那些失败退市的,被指数剔除出成分股、甚至是破产的股票很有可能成为你测试的盲点。
就以纳斯达克 100 指数、标准普尔 500 指数来说,当前他们的成分股和 20 年前纳入该指数的股票有很大出入。当使用在财经新闻中找到的当前指数成分进行回测时,数据通常仅包含“幸存者”,结果自然会被隐形的优化。但是回到过去,我们是无法判断哪些股票会出问题,从而提前避开的。
所以我们特别需要关注回测时使用的数据集是否包含了完整的历史数据。
举例介绍
本网站内的大部分回测均使用 Wealth Lab 完成,软件内置针对 DOW 30,NASDAQ 100 和 S&P 500 的数据集,同时支持通过插件和 API 接入第三方的数据源(可能需要付费)。软件会根据我们设置的优先级对数据进行读取和使用。

如上图展示,当我们查看 NASDAQ 100 指数的信息时,发现这个数据集当中包含了 320 只股票,有一些股票的代码后面有日期,用来记录清单的变化情况。这样可以帮助我们将回测中的幸存者偏差效应降到最低。
我们查看一个回测的数据对比:
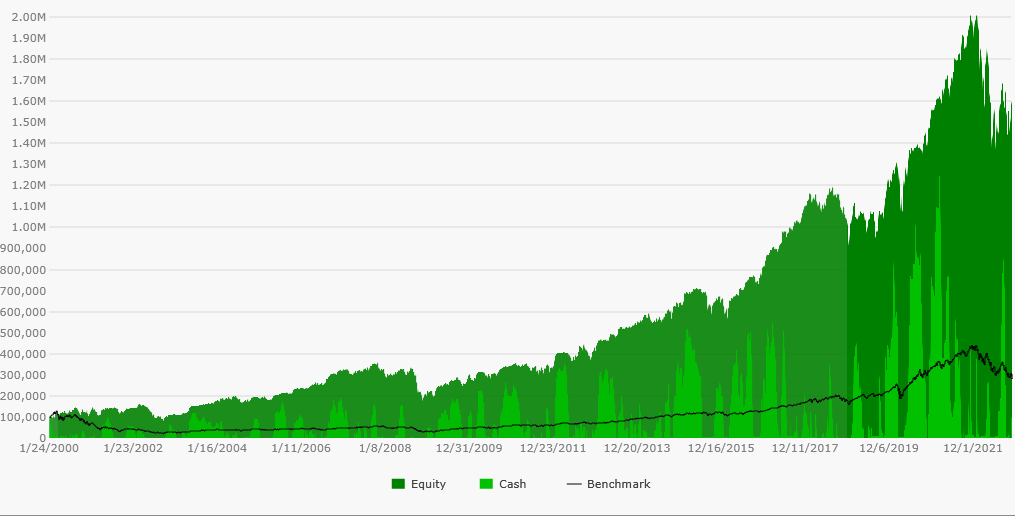

上面的两幅图中,绿色表示账户资产走势,而黑色线表示参照对象 QQQ 的走势。第一个的业绩明显优于 QQQ,而第二个则大幅度跑输 QQQ。但这 2 个回测表现来自同一个策略,唯一的差别就是使用的数据集。
因此当使用幸存者偏差数据时,可能我们会测试出一个表现非常好的策略,但将其应用到真实情况时则会面临巨大的亏损。
上图中使用的策略设置:
当 RSI(14) 低于 30 时,定投头寸,每天购买 1%
当 RSI(14) 高于 70 时,卖出所有头寸。
股票池:Nasdaq 100
参照对象:QQQ
数据范围:2000 年 1 月 1 日至 2022 年 4 月 11 日
启动资金:100,000 美元
总结 - 回测时需注意的问题
Survivorship Bias 幸存者偏差
使用含有幸存者偏差的数据,可能会给我们带来巨大的误导。
Peeking 数据窥视
数据窥视是指我们在回测中错误引用了来自未来的数据,导致了回测结果异常的优越。
Over Optimization 过度优化
过度优化是指优于过度的调整导致参数设置仅对过往的走势有效,完美贴合了过去的走势,而无法真正应用在实际未知的市场中。
订阅
谢谢阅读,你可以访问网站介绍📑,更好了解本站。
如果喜欢这篇内容,欢迎订阅、评论并分享给好友❤️;
如果不喜欢,希望你留下建议,并分享给你讨厌的人😜。